基于SSH实现模特人才招聘网站
本文共 304 字,大约阅读时间需要 1 分钟。
本项目基于SSH框架开发实现,前端采用JQUERY+CSS进行交互处理,功能完整,用户体验较好。开发工具为Eclipse或IDEA,数据库采用MYSQL数据库。
系统分为三个角色:
个人用户:可以注册,填写简历,应聘企业发布的职位,管理查看个人的应聘信息
企业用户:可以注册,发布职位,管理查看应聘的个人信息
管理员:可以管理个人用户和企业用户的相关信息。
部分功能展示:
人才库
企业列表
个人登陆注册:
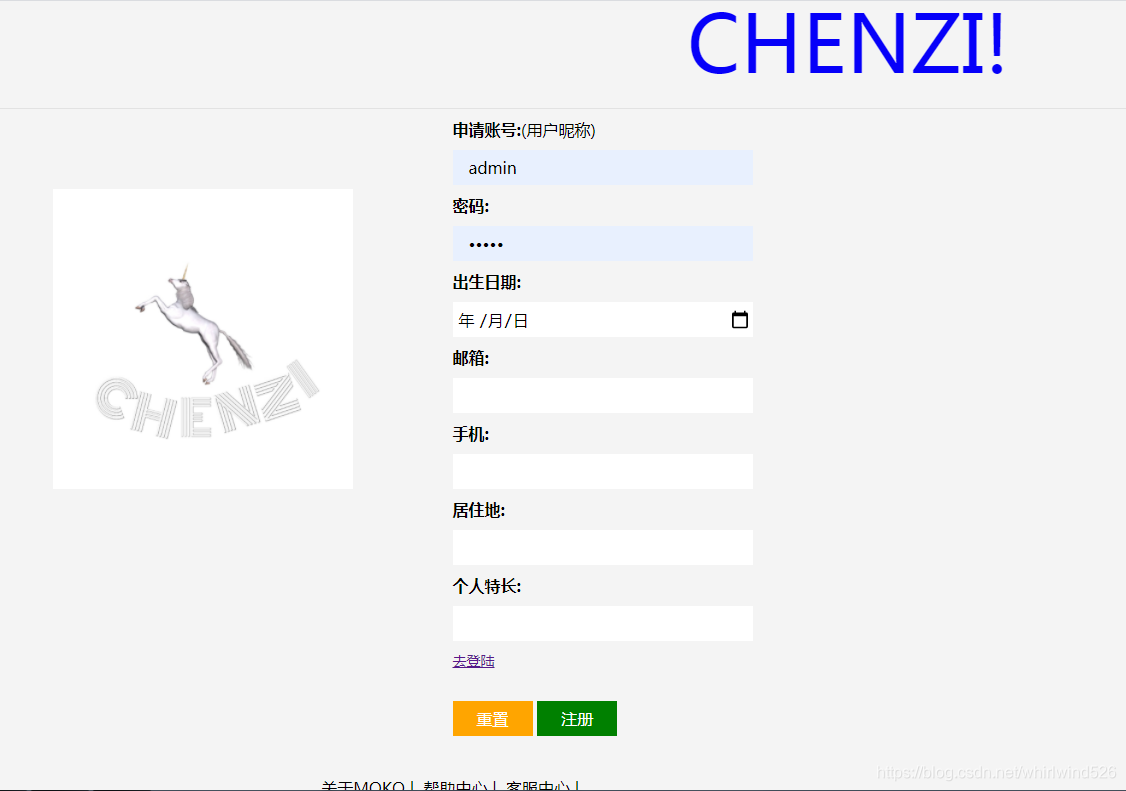
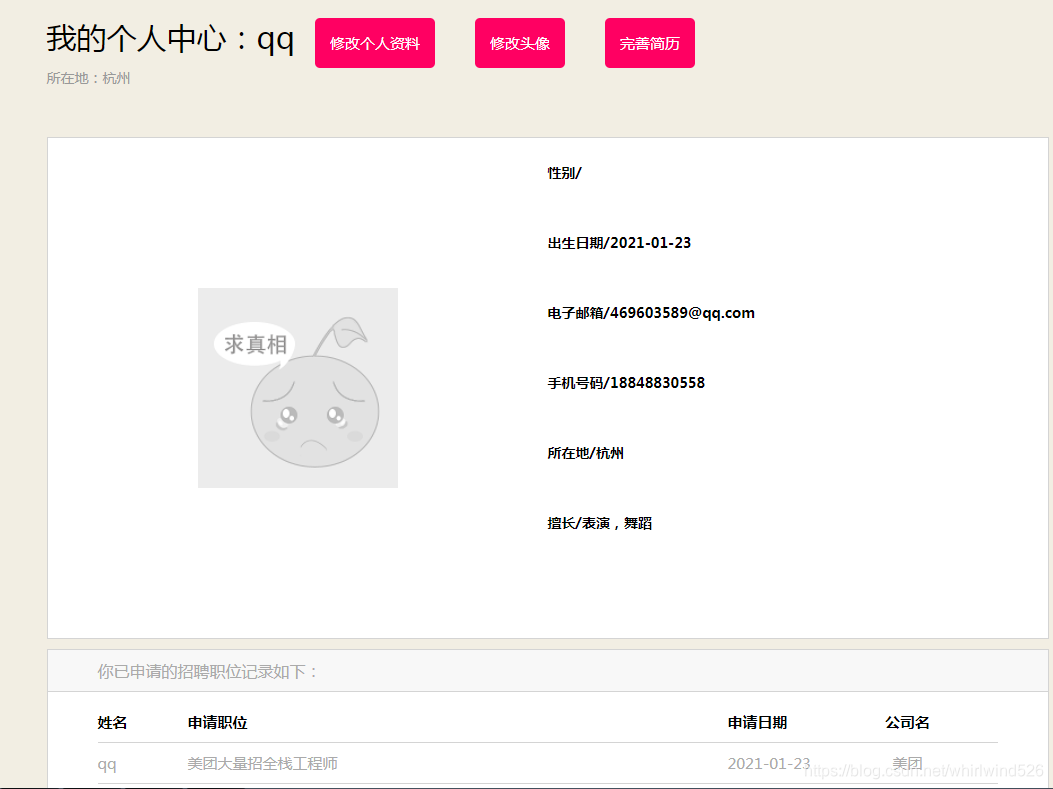
个人中心
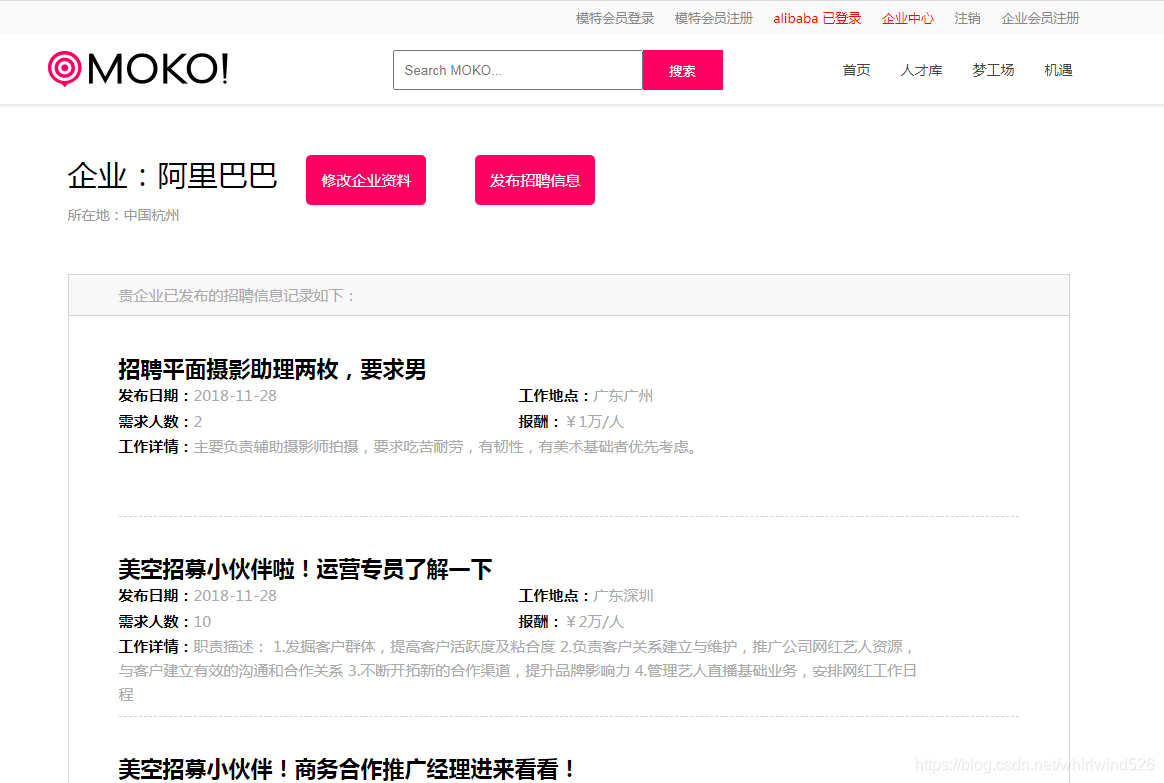
企业登陆后:
企业中心:
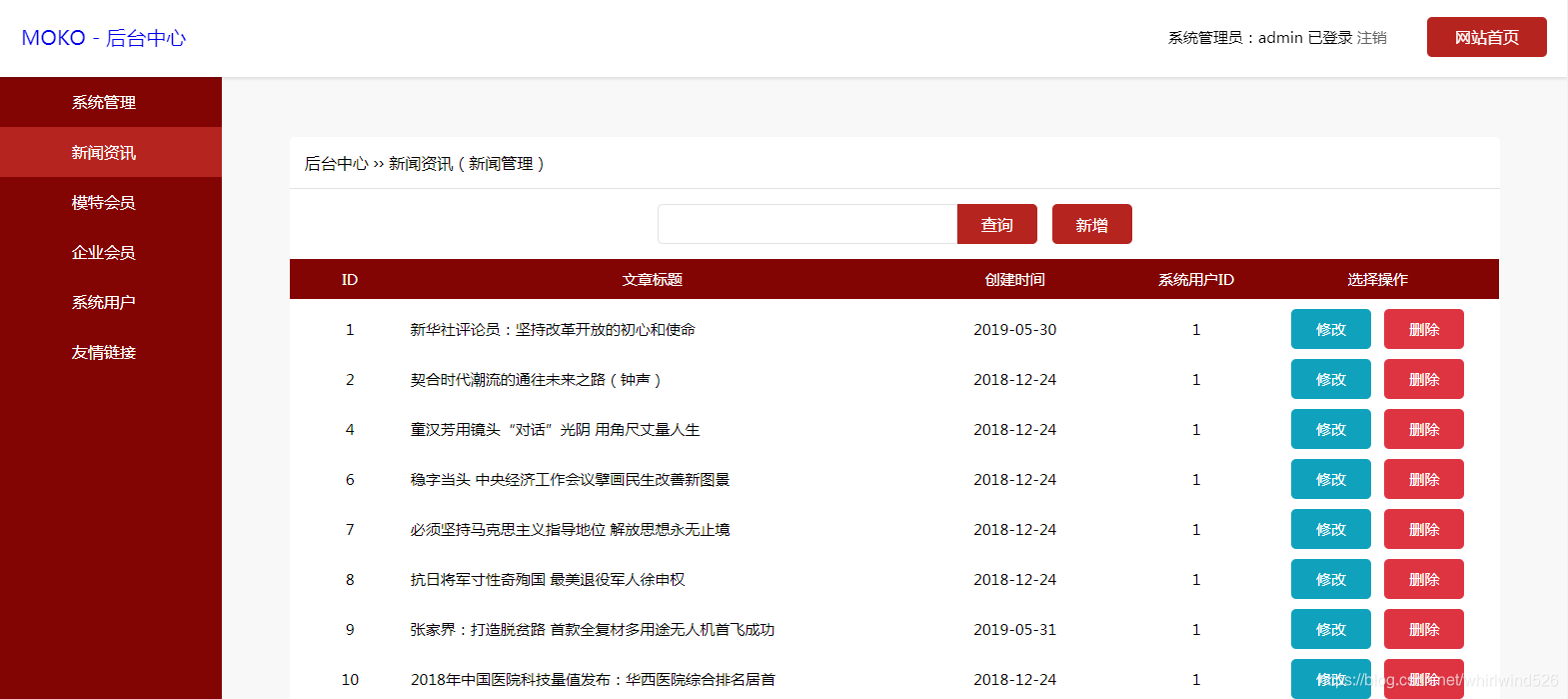
管理员登陆:

新闻管理:
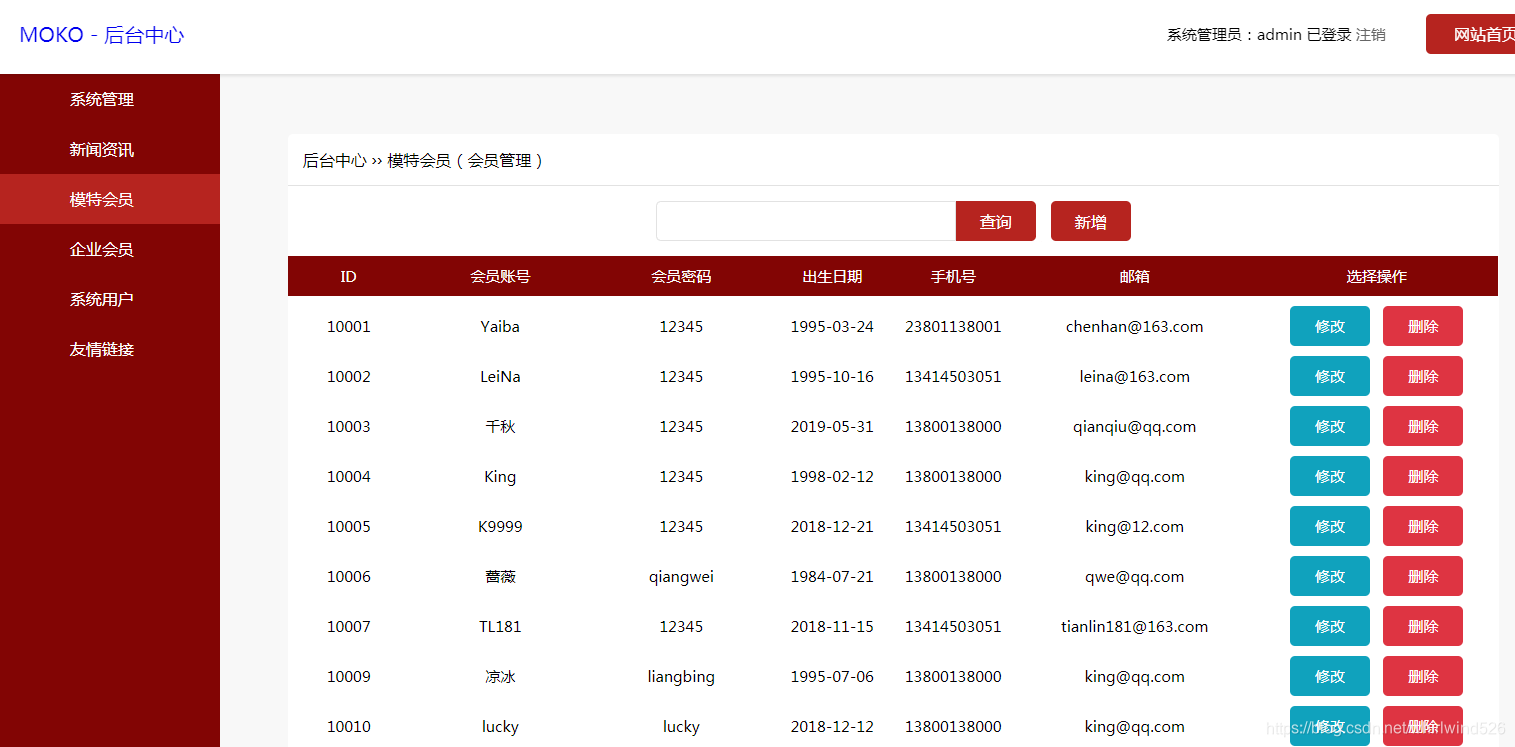
模特会员管理:
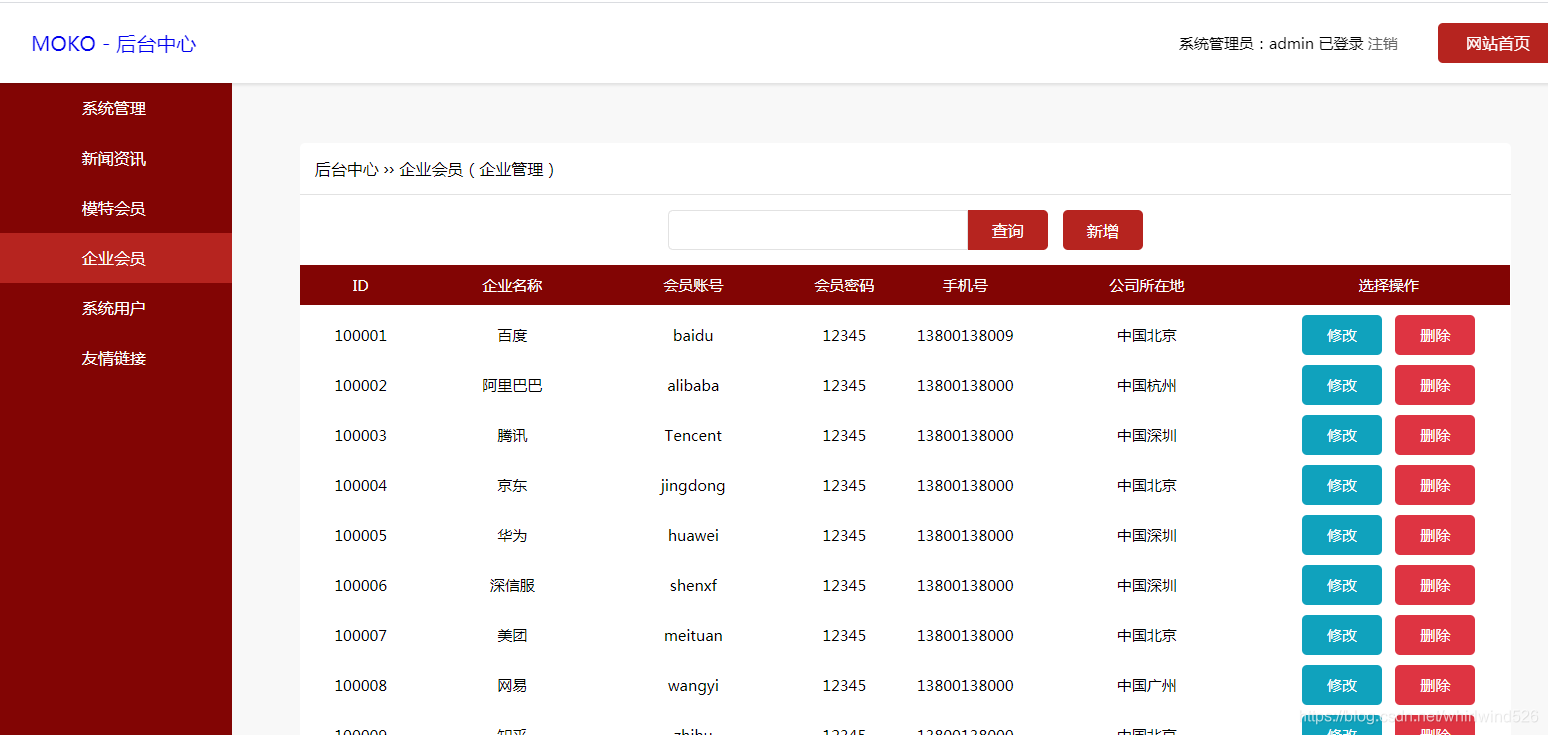
企业会员管理:
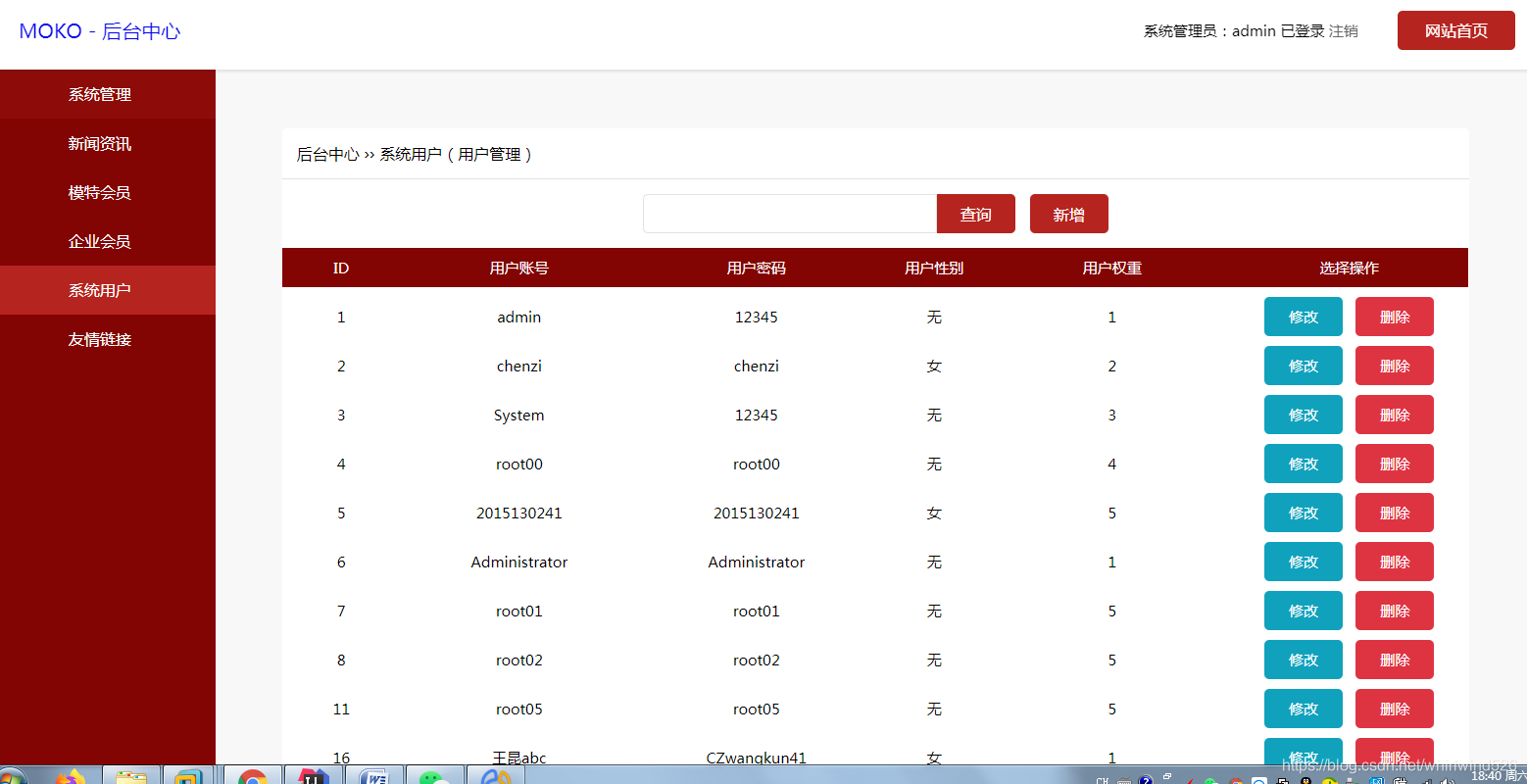
系统用户管理:
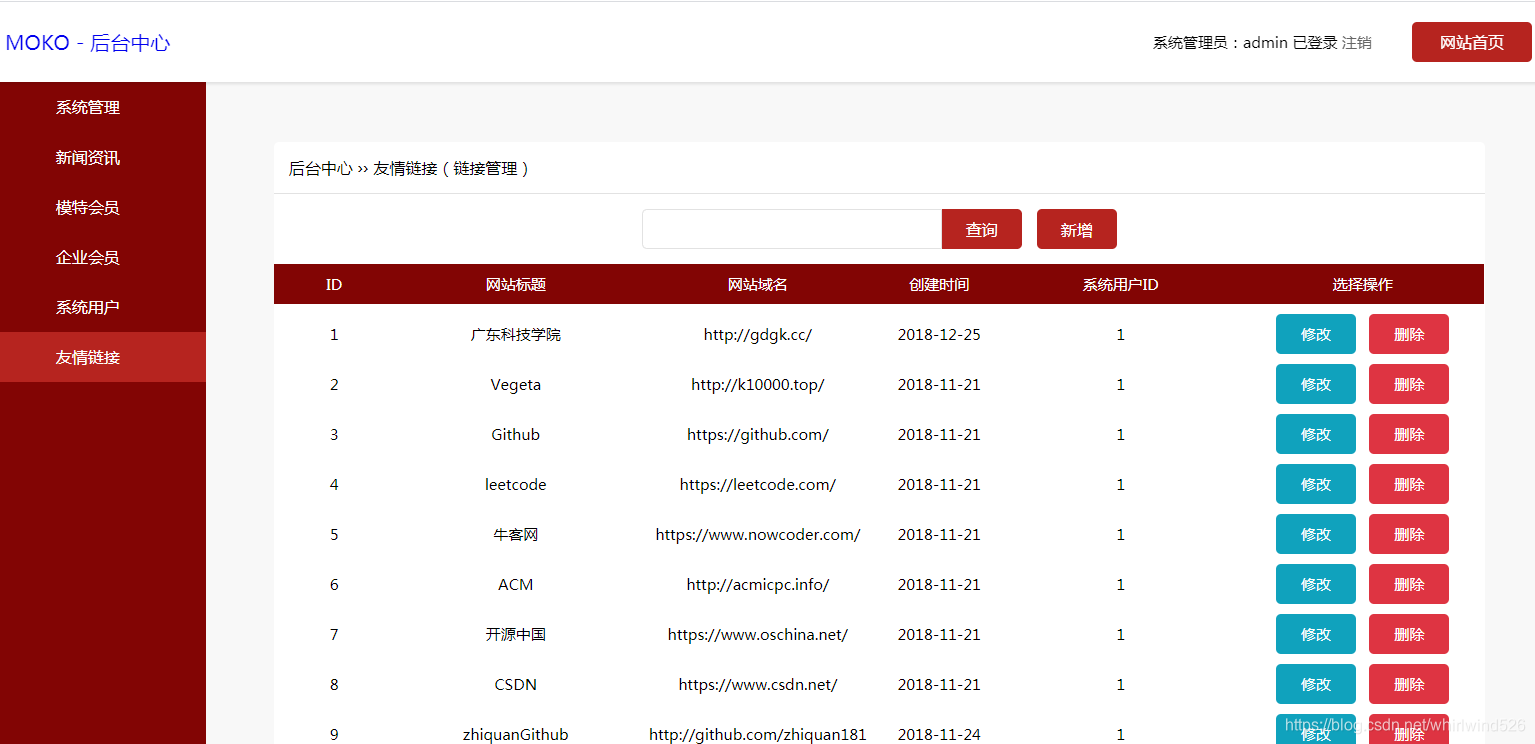
友情链接管理:
以上是模特人才招聘网站的系统功能展示,本项目运行完整,适合做毕业设计使用。
转载地址:http://dimb.baihongyu.com/
你可能感兴趣的文章
mysql 断电数据损坏,无法启动
查看>>
MySQL 日期时间类型的选择
查看>>
Mysql 时间操作(当天,昨天,7天,30天,半年,全年,季度)
查看>>
MySQL 是如何加锁的?
查看>>
MySQL 是怎样运行的 - InnoDB数据页结构
查看>>
mysql 更新子表_mysql 在update中实现子查询的方式
查看>>
MySQL 有什么优点?
查看>>
mysql 权限整理记录
查看>>
mysql 权限登录问题:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)
查看>>
MYSQL 查看最大连接数和修改最大连接数
查看>>
MySQL 查看有哪些表
查看>>
mysql 查看锁_阿里/美团/字节面试官必问的Mysql锁机制,你真的明白吗
查看>>
MySql 查询以逗号分隔的字符串的方法(正则)
查看>>
MySQL 查询优化:提速查询效率的13大秘籍(避免使用SELECT 、分页查询的优化、合理使用连接、子查询的优化)(上)
查看>>
mysql 查询数据库所有表的字段信息
查看>>
【Java基础】什么是面向对象?
查看>>
mysql 查询,正数降序排序,负数升序排序
查看>>
MySQL 树形结构 根据指定节点 获取其下属的所有子节点(包含路径上的枝干节点和叶子节点)...
查看>>
mysql 死锁 Deadlock found when trying to get lock; try restarting transaction
查看>>
mysql 死锁(先delete 后insert)日志分析
查看>>